R-FCN是在Faster R-CNN的框架上进行改造,第一,把base network由VGG16换成了ResNet,第二,把Fast R-CNN换成了先用卷积做prediction,再进行ROI pooling。由于ROI pooling会丢失位置信息,故在pooling前加入位置信息,即指定不同score map负责检测目标的不同位置。pooling后把不同位置得到的score map进行组合就能复现原来的位置信息。
Introduction
分类需要特征具有平移不变性,检测则要求对目标的平移做出准确响应。现在的大部分CNN在分类上可以做的很好,但用在检测上效果不佳。SPP,Faster R-CNN类的方法在ROI pooling前都是卷积,是具备平移不变性的,但一旦插入ROI pooling之后,后面的网络结构就不再具备平移不变性了。因此,本文想提出来的position sensitive score map这个概念是能把目标的位置信息融合进ROI pooling。
对于region-based的检测方法,以Faster R-CNN为例,实际上是分成了几个subnetwork,第一个用来在整张图上做比较耗时的conv,这些操作与region无关,是计算共享的。第二个subnetwork是用来产生候选的boundingbox(如RPN),第三个subnetwork用来分类或进一步对box进行regression(如Fast RCNN),这个subnetwork和region是有关系的,必须每个region单独跑网络,衔接在这个subnetwork和前两个subnetwork中间的就是ROI pooling。我们希望的是,耗时的卷积都尽量移到前面共享的subnetwork上。因此,和Faster RCNN中用的ResNet(前91层共享,插入ROI pooling,后10层不共享)策略不同,本文把所有的101层都放在了前面共享的subnetwork。最后用来prediction的卷积只有1层,大大减少了计算量。

R-FCN
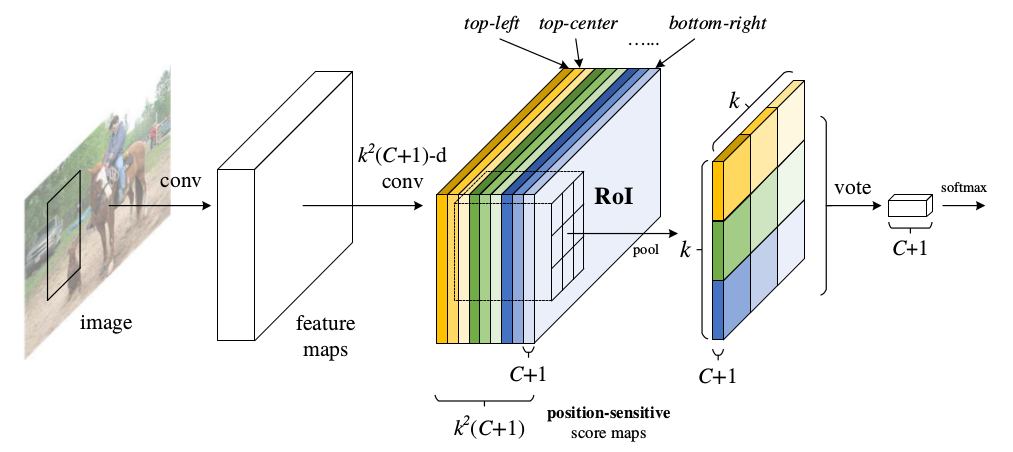
Backbone architecture: ResNet 101——去掉原始ResNet101的最后一层全连接层,保留前100层,再接一个
1*1*1024的全卷积层(100层输出是2048,为了降维,引入了一个1*1的卷积层)。$k^2(C+1)$的conv: ResNet 101的输出是
W*H*1024,用$k^2(C+1)$个1*1*1024的卷积核去卷积即可得到$k^2(C+1)$个大小为W*H的position sensitive的score map。这步的卷积操作就是在做prediction。例如k = 3,表示把一个ROI划分成3*3,对应的9个位置分别是:上左(左上角),上中,上右,中左,中中,中右,下左,下中,下右(右下角)。$k^2(C+1)$个feature map的物理意义: 共有
k*k = 9个颜色,每个颜色的立体块(W*H*(C+1))表示的是不同位置存在目标的概率值(第一块黄色表示的是左上角位置,最后一块淡蓝色表示的是右下角位置)。共有$k^2(C+1)$个feature map。每个feature map,z(i,j,c)是第i+k(j-1)个立体块上的第c个map(1<= i,j <=3)。(i,j)决定了9种位置的某一种位置,假设为左上角位置(i=j=1),c决定了哪一类,假设为person类。在z(i,j,c)这个feature map上的某一个像素的位置是(x,y),像素值是value,则value表示的是原图对应的(x,y)这个位置上可能是人(c=‘person’)且是人的左上部位(i=j=1)的概率值。ROI pooling的输入和输出:ROI pooling操作的输入(对于C+1个类)是$k^2\times (C+1)\times W’\times H’$(W’和H’是ROI的宽度和高度)的score map上某ROI对应的那个立体块,且该立体块组成一个新的$k^2\times (C+1)\times W’\times H’$的立体块:每个颜色的立体块(C+1)都只抠出对应位置的一个bin,把这
k*k个bin组成新的立体块,大小为$(C+1)\times W’\times H’$。例如,上图中的第一块黄色只取左上角的bin,最后一块淡蓝色只取右下角的bin。所有的bin重新组合后就变成了类似右图的那个薄的立体块(图中的这个是池化后的输出,即每个面上的每个bin上已经是一个像素。池化前这个bin对应的是一个区域,是多个像素)。ROI pooling的输出为为一个$(C+1)\times k\times k$的立体块。vote投票:
k*k个bin直接进行求和(每个类单独做)得到每一类的score,并进行softmax得到每类的最终得分,并用于计算损失。训练的样本选择策略:online hard example mining (OHEM) 。主要思想就是对样本按loss进行排序,选择前面loss较小的,这个策略主要用来对负样本进行筛选,使得正负样本更加平衡。
两个关键层:
- 包含多个 Score Map 的卷积层:把目标分割成了
k*k个部分(比如3*3),每个部分映射到一张 Score Map 上,每个 Score Map 对应目标的一部分(如上图中的 top-left 左上角的 1/9)。最终得到k*k个Score Map,每一个 Map通道数为 分类个数 C+1。 - 一个 ROI Pooling 层:这个 ROI 层仅针对上面的其中一个 Score Map 执行 Pooling 操作,重新排列成
k*k,通道数为 C+1。ROI Pooling 层通过k*k个 Part 进行投票,得到分类结果。

- 包含多个 Score Map 的卷积层:把目标分割成了