这篇文章在既保证速度,又要保证精度的情况下,提出了SSD物体检测模型。SSD将检测过程整个成一个single deep neural network,便于训练与优化,同时提高检测速度。SSD将输出一系列离散化的bounding boxes,这些bounding boxes是在不同层次上的 feature maps上生成的,并且有着不同的aspect ratio。
Introduction
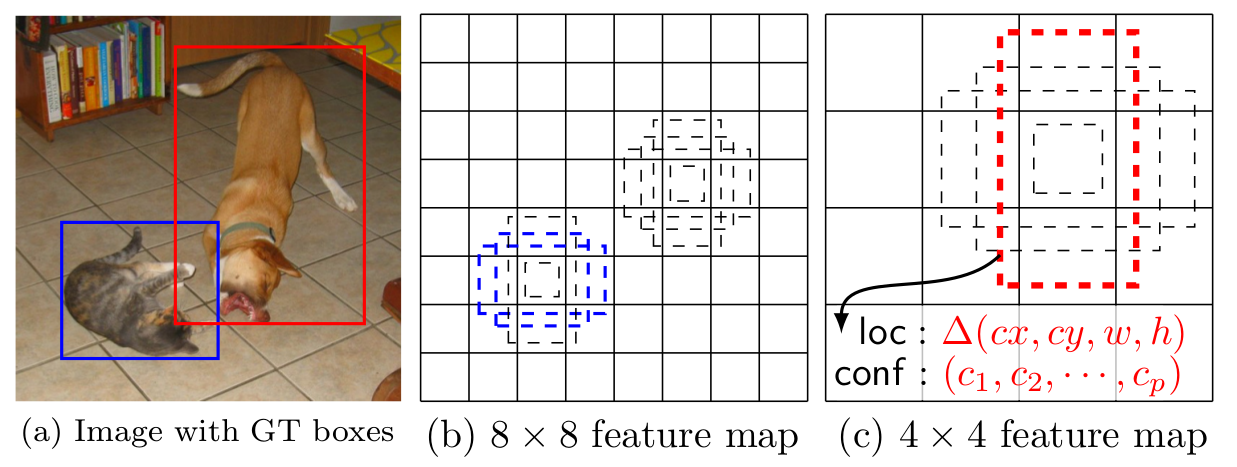
SSD的特殊之处主要体现在以下3点:
- 多尺度的特征图检测(Multi-scale),如SSD同时使用了上图所示的
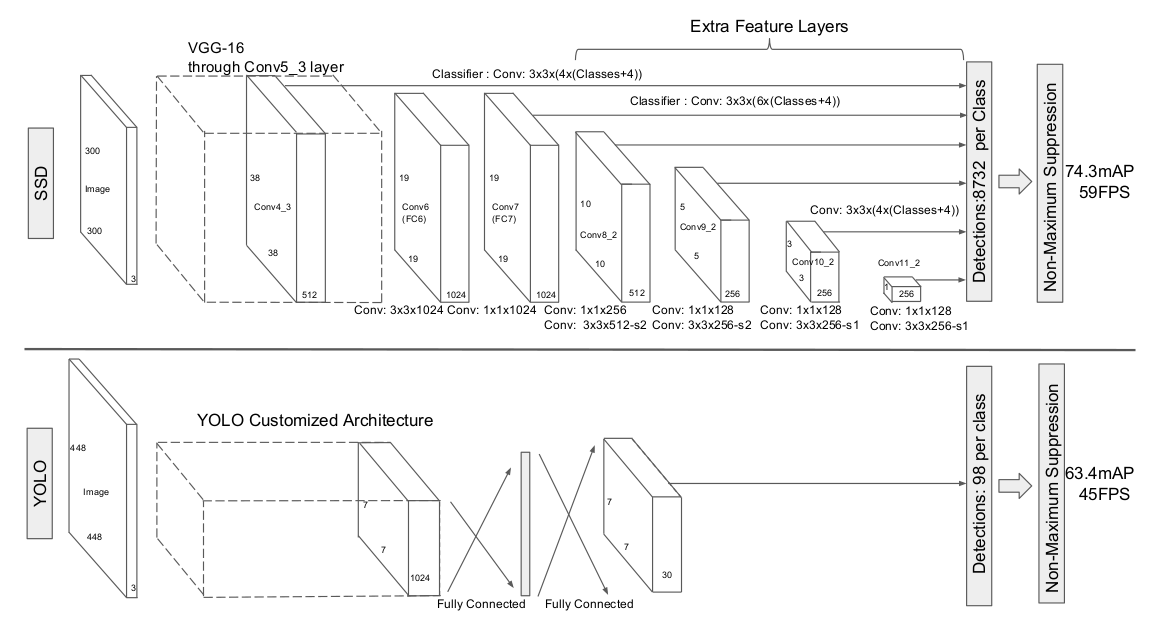
8*8的特征图和4*4特征图。 - 相比于YOLO,作者使用的是卷积层来代替了YOLO的全连接层做预测。(如下图所示)
- SSD使用了默认的边界框+(1,2/1,3/1,1/2,1/3)6个框来做检测(aspect ratios)
SSD网络训练技巧
SSD能达到这么高的检测精度离不开它所采用的训练技巧。

1. 数据增强
SSD训练过程中使用的数据增强对网络性能影响很大,大约有6.7%的mAP提升。
- 随机剪裁:采样一个片段,使剪裁部分与目标重叠分别为0.1, 0.3, 0.5, 0.7, 0.9,剪裁完resize到固定尺寸。
- 以0.5的概率随机水平翻转。
2. 是否在基础网络部分的conv4_3进行检测
基础网络部分特征图分辨率高,原图中信息更完整,感受野较小,可以用来检测图像中的小目标,这也是SSD相对于YOLO检测小目标的优势所在。增加对基础网络conv4_3的特征图的检测可以使mAP提升4%。
3. 使用瘦高与宽扁默认框
数据集中目标的开关往往各式各样,因此挑选合适形状的默认框能够提高检测效果。作者实验得出使用瘦高与宽扁默认框相对于只使用正方形默认框有2.9%mAP提升。
4. 使用atrous卷积
通常卷积过程中为了使特征图尺寸特征图尺寸保持不变,通过会在边缘打padding,但人为加入的padding值会引入噪声,因此,使用atrous卷积能够在保持感受野不变的条件下,减少padding噪声,关于atrous参考。本文SSD训练过程中并且没有使用atrous卷积,但预训练过程使用的模型为VGG-16-atrous,意味着作者给的预训练模型是使用atrous卷积训练出来的。使用atrous版本VGG-16作为预训模型比较普通VGG-16要提高0.7%mAP。