传统CNN通过扩增数据获得数据的一些不变性,如旋转不变性,平移不变性等,是一种隐式的学习,而空间变换网络(Spatial Transformer Networks,简称STN)通过显式学习数据的各种变换参数(如旋转,平移,仿射变换等)来获得这些变换的不变性。这个网络可以很方便的插入到已有的CNN网络中。
Introduction
- 不变性(invariance):在CNN中,pooling层使得网络对位置的敏感度越来越低,从而使网络具有一定的平移不变性。这种空间不变性是通过多层的conv和pooling层实现的,而且对变换较大的输入数据并不具有不变性。
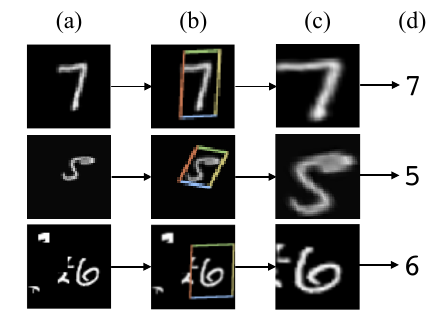
- Spatial Transformer: 引入空间变换模块(spatial transformer module),可以添加到任何一个标准的神经网络结构中,从而提供空间变换的能力。与pooling层不同,空间变换模块是一个动态的机制,训练得到合适的变换参数,然后将这个变换应用在整个feature map上,可以覆盖scaling, cropping, ratations等变换。这样的好处是可以使得网络选择出一幅图像中最相关的区域,如下图所示,(a)是输入图像,(b)是空间变换模块预测的定位结果,(c)是空间变换后的结果,(d)是分类结果。
- 应用:STN可以嵌入CNN中实现不同的任务,例如:
- image classification: STN可以crop out和scale-normalize合适的区域,简化接下来的分类任务,提高分类性能;
- co-localisation: 不需要标记目标的位置,通过STN,可以定位目标;
- spatial attention: 可以实现attention机制,很灵活,无需增强学习。
Spatial Transformers
由以下三部分组成
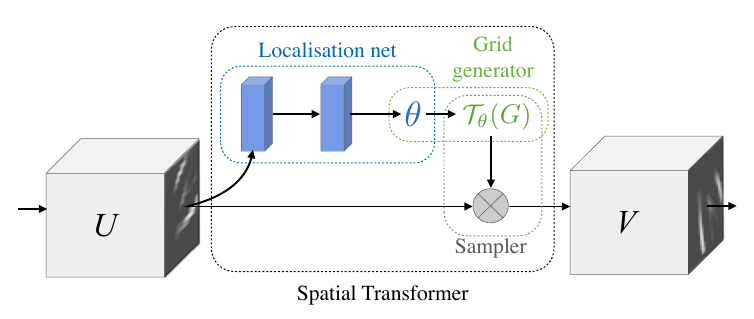
- Localisation Network: 输入feature map,输出$\theta$。$\theta$的尺寸取决于变换类型,比如对于仿射变换,$\theta$就是6维的。这个网络可以采用任意形式,比如全连接网络或卷积网络,但是最后应该有一个回归层输出参数$\theta$。
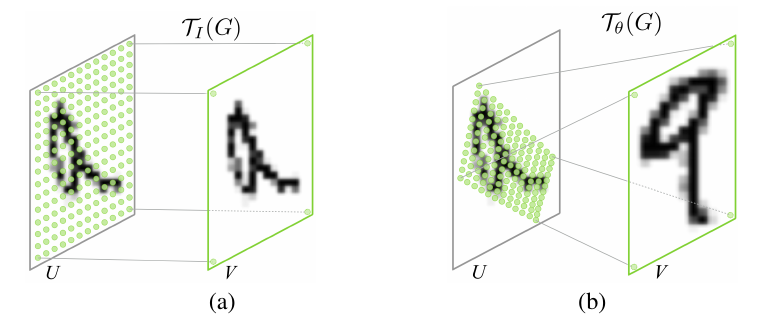
- Parameterised Sampling Grid: 以下是将Parameterised Sampling Grid应用到图像U上得到输出V的两个例子,图(a)是一个单位变换,图(b)是一个仿射变换。
- Differentiable Image Sampling: 这一步是将输入的feature map结合变换参数,输出结果feature map。
个人总结
传统CNN通过各种数据扩增操作来获得某些不变性(如平移不变性,旋转不变性等),是一种“隐式学习”的方法,即我们只是向网络输入数据,直接输出的就是预测结果。而STN主要是一种“显式学习”空间变换参数的方法,它通过训练得到这些参数,对输入数据(也可以是中间的feature map)进行变换,使得后续的处理能得到更好的结果。
- 优点:容易扩展,可以很方便的嵌入其它网络中;与CNN是直接识别出扭曲图像不同,
STN显然更符合人类识别的过程,即先将图像纠正再识别。 - 缺点:训练时依然需要大量数据扩增才能学到所需要的不变性,而且学习到的变换参数不一定是我们希望的。
复现过程:
对Mnist数据集进行随机旋转,然后使用论文中提到的超参数设置,结果显示采用STN后在测试集上的准确率确实高于不使用STN的时候。但是对STN层后的输出进行可视化后并没有原文中效果那么好,比如我需要学习的是旋转不变性,但是结果显示STN层所做的事情是平移而不是旋转。我认为可能在学习旋转不变性时需要固定6个变换参数中的某几个,使得能够显式的学习旋转不变性。